

Assembli
Assembli is a reference platform for researching guardrail strategies that make AI conversational apps and Large Language Models (LLM) safe for business use cases, including customer support, field service, financial analytics, knowledge work and numerous enterprise front and back office applications.
There is growing sentiment that LLM AI (e.g., ChatGPT, Claude, Gemini) are not ready for prime time in terms of reliability and information safety for business-critical applications.
The concern is valid, but in actuality, it's possible with the approach discussed below to use Machine Learning (ML), Natural Language Processing (NLP) and Information Retrieval (IR) methodologies to mitigate AI business hazards.
"Dr. John Halamka, Mao Clinic's AI Czar, on the need for guardrailing AI apps with machine learning and related deterministic data processing methods (short video clip):
AI's version of the dot.com bubble: Some of the best machine learning minds today agree that Large Language Models (LLM) can become very inaccurate when they are working outside their "distribution" (their training corpus). And even when inside their parametric knowledge space, LLMs can be very inconsistent due to the probabilistic nature of transformer inference. Unfortunately, many AI solution providers have tried to fix LLM shortcomings with just "more AI" , as opposed to the ML/NLP/IR guardrails that Plexgraf recommends.
This explains why so many major AI business app projects have failed across numerous industries. And it explains why the AI industry is thrashing around with complex prompt engineering, expensive model fine tuning, adaption layers, custom pre-training, in-context learning, agent networks, multi-step decision flows etc., without any actual practical, deterministic AI solution that the average business can deploy with confidence.


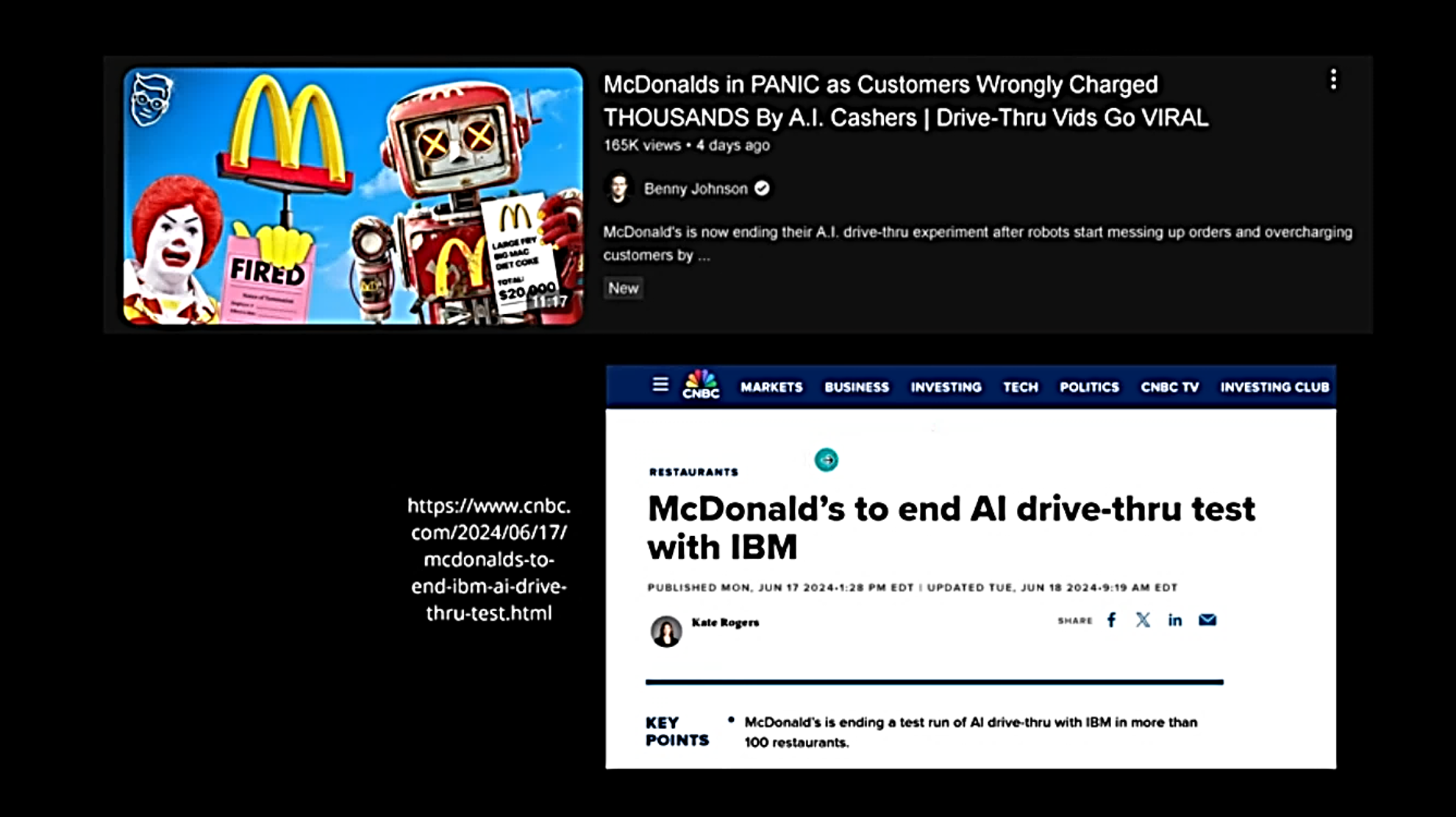
Examples of a high-visibility AI projects that failed to deliver needed accuracy and consistency:

Stanford ML/AI courses and books spell out danger:

Explicit cautions from Google about AI threats:

Business Realities for AI
If AI applications and chatbots are to succeed, there's 4 huge challenges to overcome:
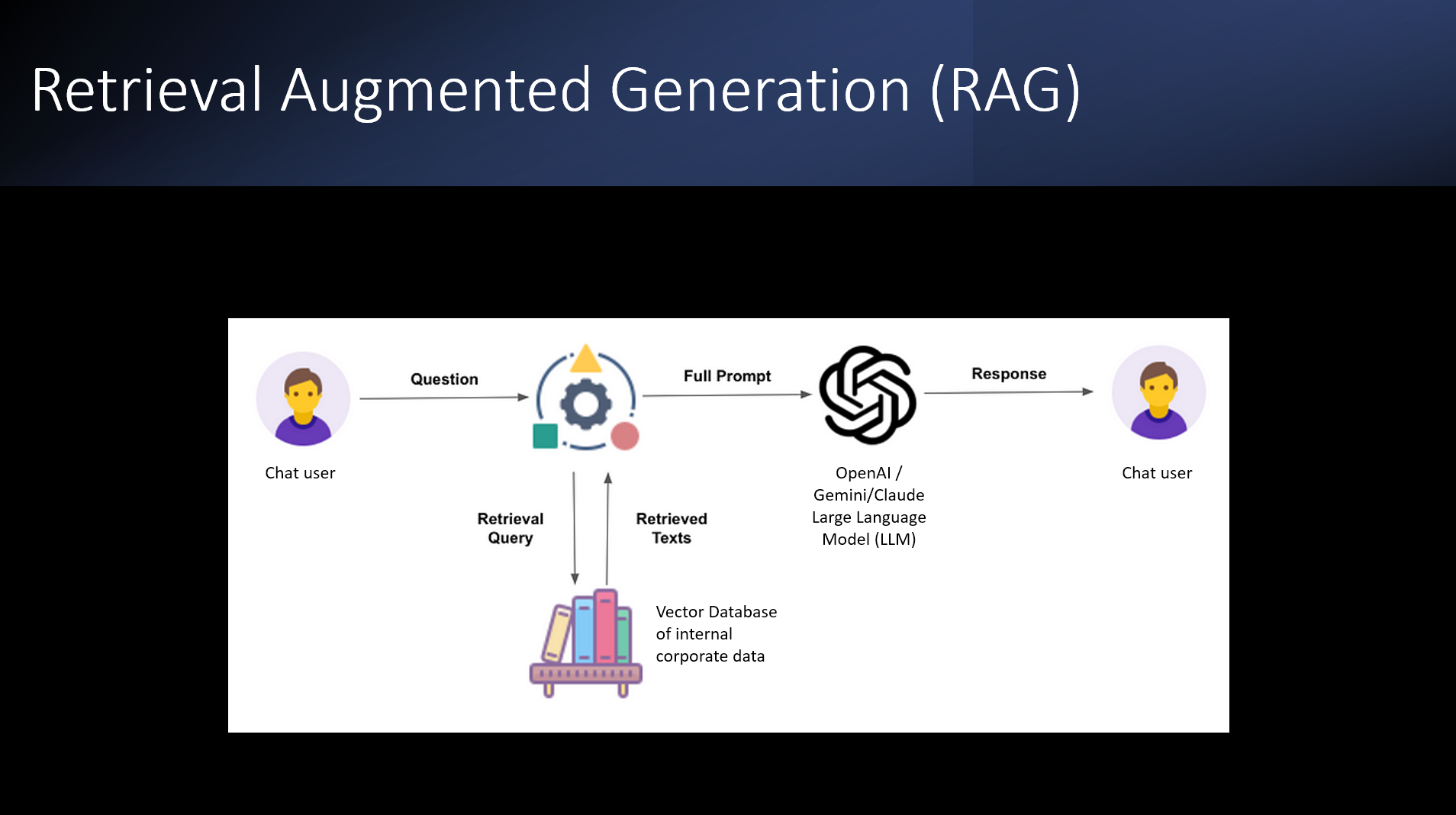
DEFINITION: Retrieval Augmented Generation (RAG). A large percentage of currently available business apps for AI are based on Retrieval Augmented Generation, an approach that injects custom business content into the prompt when chatbot users send questions to AI LLMs. RAG is dangerous for business apps unless it's guardrailed with mature ML/NLP/IR techniques, as per the Assembli approach.
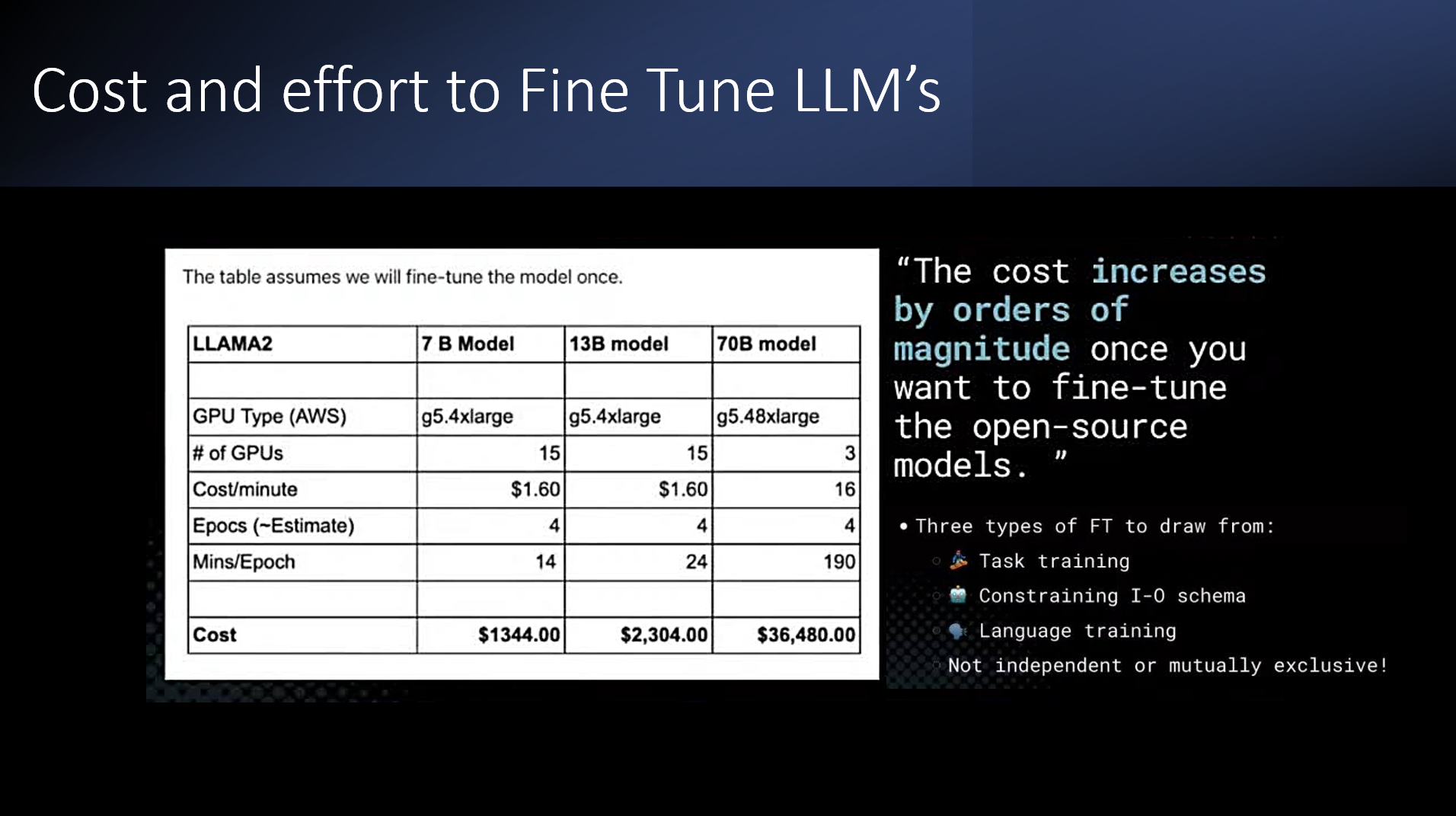
DEFINITION: Fine Tuning (FT). Another approach to enhancing LLMs is fine tuning, which uses supervised or semi-supervised learning to train a 'vanilla' LLM on a vertical knowledge domain or specific tasks that are needed in a business workflow. Fine tuning is expensive, time-consuming and can lead to conflicts between original training data and fine-tuned instructions. Assembli avoids repeated fine tuning efforts by putting the real-time dynamic aspect of the knowledge base in mature ML/NLP/IR and DBMS resources.
THE HALLUCINATION PROBLEM
LLM's hallucinate and give wrong or inappropriate answers: Hallucinations are a natural part of the large language model landscape because of the non-deterministic way that transformer networks process information... it's organic, it's emergent, its creative, it's adaptive.... it's also prone to errors that business applications can't tolerate. It's not practically possible to eliminate factual errors to the level needed by business applications with RAG and FT.
SOLUTION
To fix the hallucinations: Readily available ML/NLP/IR techniques can create a controlled set of concepts and vocabularies that serve as guardrails for LLM agents and chatbots.
THE HUMAN LOOP PROBLEM
AI apps need a human loop: LLMs Don't naturally lend themselves to being chopped up into discrete process steps, ie, what you expect from transactional or analytical enterprise applications and database driven flows.
SOLUTION
To fix the human loop: Assembli orchestrates humans into AI app flow at just the right points in the end-to-end process so that problem escalation, human oversight, sentiment response, shared problem solving happen when they should. Assembli does the human loop via a Knowledge Response Center platform that is very tightly coupled to the LLM workflow and chatbot activity.
THE REAL-TIME LEARNING PROBLEM
LLMs don't learn in real time: They are largely static between major re-training efforts, which are computationally expensive and time consuming. And even then the LLM is not an ideal stand-alone knowledge repository because there are limits to it's retrieval modalities - LLSs are not inherently accurate information retrieval (IR) engines that can handle a vast array of structured and semi-structured data.
SOLUTION
To fix the learning problem: Assembli provide a Knowledge Response Center that builds a canonical living, real time store for human and bot knowledge. the Response Center helps in many ways. For instance when a QA chatbot AI need to be seeded with canonical answers, humans work together in the Knowledge Response Center to create an answer set. When a problem the bots can't handle arises, humans convene in the Response Center, solve the problem and it becomes part of the Assembli knowledge corpus for the access via bots and humans using a wide range of AI and conventional data management modalities.
THE COST AND SCALABILITY PROBLEM
AI: expensive to build and maintain: As shown below, the cost of fine tuning can be huge, especially if it is repeated often due to changing business content, product features, business model, etc. For business-critical AI applications the costs spiral when it comes to " the last mile" that gets you to a whole solution.
SOLUTION
To fix the scaling and expense problem: Assembli overcomes the high-costs and low quality of RAG/FT AI with a knowledge graph-based Knowledge Response Center, which compliment LLM's in many important ways. The knowledge graph DBMS repository and IR guardrail system can scale and adapt to rapidly changing business environments and customers needs very cost effectively.
LLM AI's are language models... networks of language. To expect them to operate like mission critical business apps that have mature structured data, databases, business rules with explicit conditional logic is wrong. It may be best to think of LLM capabilities like the skills of a brilliant personality who is not entirely trustworthy or predictable, but can be hugely productive with the right guardrails and safety nets. Assembli provides the guardrails and safety nets with well architected ML/NLP/IR schemas, ontologies and flow logic.

The Plexgraf Solution
If AI-based business apps are to support customers reliably, conventional context augmentation ( i.e., RAG) must be wrapped in an ML/NLP/IR architecture that guides the LLM into the correct knowledge domain. In the case of the hotel guest hearing about yoga when they wanted the gym hours, the IR will acquire a set of domain vocabulary via very precise synonym matching and feed that to the LLM along with other context and the user query so the answer is correct.
In addition to ML/NLP/IR enhancements for AI, there is a need to architect a human loop that brings humans into the agent flow at precisely the correct point in time. Hence, Plexgraf creates a reusable, repurposable adaptive repository of augmented knowledge objects so that AI's and humans can reason together across this fabric in a flexible open ended way.
Solution Summary
The Plexgraf Assembli testbed develops solutions for AI-driven customer support and employee knowledge apps with a goal of delivering reliable workflows that orchestrate AI / human collaboration... "brain/bot" learning loops!
Assembli can be thought of as a multi-agent ‘rhizomatic’ (an organically branching network) platform for brain / bot collaboration. Assembli creates a persistent repurposable knowledge store that lives alongside the AI LLM, enabling precision hand-offs between humans and bots.
Assembli uniquely addresses cross-discipline problem-solving in the AI age with an approach that is based on over 50 years of combined experience in information retrieval engineering (IR), natural language text processing (NLP), machine learning (ML) and conversational interfaces,
Assembli Building Blocks
AI applications typically manifest as AI chatbots or intelligent proactive ai agents that answer questions and help with operational workflows such as sales, product support, medical issues, travel ticketing, content creation, etc.
Virtual Assistant Chatbots are the workhorse of many corporate AI apps but they are notorious for poor accuracy and consistency (e.g., retrieval F1 < 80%). Making API calls from a business-critical application directly to a public LLM service is typically not going to result in reliable or secure end-user conversations. The Plexgraf approach is to use inside-the-firewall AI resources and shoot for retrieval precision / recall metrics that are as close to 100% as possible. The starting point for this exercise is to document capabilities of the LLM in relation to the target corporate application and conduct extensive testing of the model, and the end to end app . This level of work often involves fine-tuning, context learning and enhanced prompt engineering using the corporate corpus.
AI Task Agents. Creation of semi autonomous AI agents that can do more than answer questions, eg, solve problems and then send email, do database queries, create reports, make API calls.
Assembli is unique in that it’s answer bots and agents operate in an heterogeneous data-rich environment that knits together:
Knowledge Response Center. AI-based customer and employee support need pin-point 'fall-back' (also called 'no-match') functions that loop in humans for escalation, sentiment, and experience that lies outside the LLM realm. Assembli provides this with a "knowledge response center' where experts and bots build a canonical knowledge repository that works hand-in-hand with the fully automated generative support bot activity.
Machine Learning & IR. Things don't bode well for organizations who try and solve all their customer and employee knowledge support needs with LLM AI alone. What's really needed is a blend of LLM AI + machine learning + information retrieval technologies knitted together with bots and humans in an elegant brains+bots architecture, i.e., Assembli !

Target Applications for AI Augmented with ML/IR
Once LLMs have been augmented by ML / NLP / IR and given a 'living' knowledge repository that collects brain/bot learnings in real time.. there’s an ideal opportunity to build automated agents and task automation apps that exploit the LLM + custom data. Here are some examples:
Each of these applications leverages the combination of the LLM's natural language understanding capabilities with the specific, contextual data of the company, providing tailored and efficient solutions to various business needs.

Quality and Safety layer
The Plexgraf multi-agent architecture addresses quality and safety issues with ‘Safety Sentry Agents” that conduct continuous monitoring and auditing of generative AI processes. The safety Sentries work off their body of augmented safety and quality knowledge that address these issues and more:
Bias and Hallucinations: AI systems are prone to factual errors and can inherit biases present in their training data, leading to unfair or sub-optimal outcomes. This is particularly concerning in sensitive areas like corporate confidentiality, research and development content, financial content and policy enforcement.
Data Privacy and Security: AI systems often rely on large amounts of personal data, raising concerns about privacy and data protection. There's also a risk of data being manipulated to skew AI decisions.
Lack of Explainability: Many AI models, especially deep learning systems, are often seen as "black boxes" due to their complexity, making it difficult to understand how they reach certain conclusions or decisions.
Robustness and Reliability: AI systems can be prone to errors or manipulation, such as adversarial attacks, where small, intentional changes to input data can lead to incorrect outputs.
Ethical and Legal Impacts: AI applications can have far-reaching impacts on society, including job displacement, surveillance concerns, and the potential for misuse in areas like autonomous weaponry.
In all the above cases, Plexgraf Safe Sentry agents comb through generated content doing cross-checking in real time looking for anomalies, mistakes and harmful texts..
AI Augmentations for Business Applications
Normally QA Conversational application interfaces and Agent task flows work on top of vanilla public LLMs (OpenAI GPT, Gemini, Anthropic, etc.) but with Assembli, QA chatbots and agents can reason across augmented LLMs that have content customized and extended by a wide range of ML / NLP / IR techniques. Business logic and structured content augmentation allows LLMs to take advantage of a company’s internal data and internal human knowledge experts, without compromising the privacy and security of that data.
How to Tame a Large Language Model (from simple to complex).
1) Conventional search. In this approach, the LLM chat bot or operational agent can do conventional search queries against public or private text bases ( e.g., Wikipedia look-ups) during the course of a chatbot session. Info found this way is not a persistent part of the LLM’s base model..
2) Best Match Text library. In addition to queries of conventional search services, vertical private data can be stored and indexed with BM25 or similar TF/ IDF methods and made available for custom queries from bots and agents.
3) Context Injection. Typical GPT and other chatbots continually look across all the prompt text a user enters to gain context during a session. Context injection allows the chatbot to incorporate new and relevant information into the conversation beyond what the user enters. This can include current events, private corporate data, in-depth research or any other data that can make the conversation more relevant and personalized. Context injection can be accomplished by searching an auxiliary content base in real time during a chatbot session and then feeding chunks of relevant info into the prompt window as background for the actual user query.
4) Vector Embedding. Text embedding stores enhance LLMs with entire documents that are mapped as vectors in a high-dimensional semantic space to capture semantic and syntactic relationships between the words or phrases. LLMs can access supplemental embedding content in the process of generative text exchanges with human base on vertical knowledge bases and specialized corporate know-how.
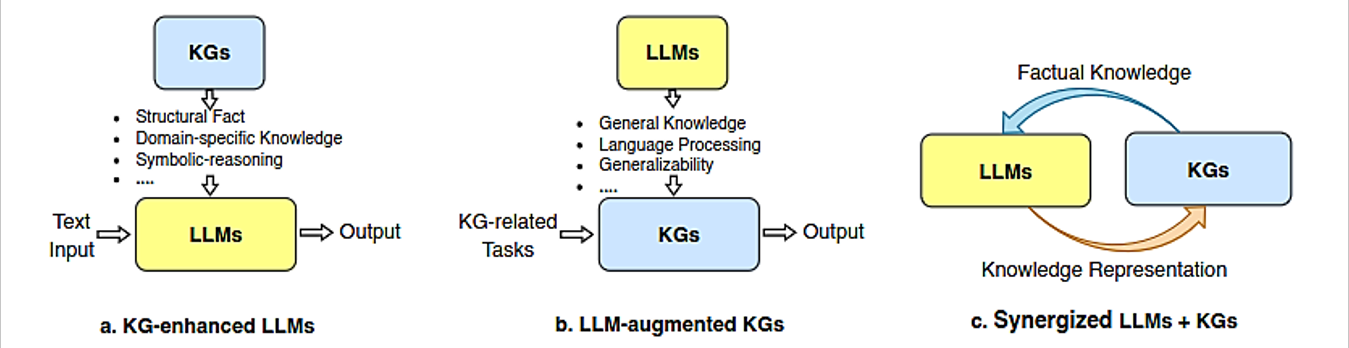
5) Knowledge Graphs. A knowledge graph, when combined with a Language Model, serves as a complementary content store that enhances the model's capabilities, enabling “Rhizomatic” knowledge sharing platforms.
6) Structured Information Store. Knowledge graphs store information in a structured format, typically in the form of entities (like people, places, events) and relationships between these entities. This structured format is different from the way information is stored in an LLM, which is primarily through weights in a neural network based on textual data.
7) Enhanced Data Retrieval. When an LLM is integrated with a knowledge graph, it can access this structured information directly. This allows for more precise and accurate retrieval of factual data, as knowledge graphs are often curated and can be more up-to-date compared to the LLM's training data.
8) LLM Fine Tuning. LLMs can be fine tuned via reinforcement learning with supplemental content from private corporate knowledge stores and domain expert content. Fine tuning often involves labeling of data to provide categorization and feedback loops for the LLM. This is typically more intensive/expensive than RAG / embedding but less effort than training an LLM neural network from scratch.
The Plexgraf platform for federated brain/bot applications is called “ Assembli ” . Think of it as StackOverflow (QA) meets Salesforce (business apps) meets vertical ‘wikipedia-esque’ knowledge stores.
Plexgraf Technical and Project Skills
|
ARCHITECTURE |
|
|
N-tier SAAS architectures |
|
|
ELK Stack (Open Search, Lucene, SoLr, Nutch) |
|
|
DBMS design |
|
|
Transaction process algo's |
|
|
Knowledge Community platforms |
|
|
Data Architecture |
|
|
SQL, NoSQL |
|
|
Enterprise Integration Patterns |
|
|
Data Warehouse design (Kimball, Inmon) |
|
|
App Based OLAP |
DuckDB |
|
|
|
|
CODING |
|
|
Python |
|
|
GO |
|
|
C# |
|
|
C++ |
|
|
Java |
|
|
Low Code development |
Google's AppSheet, N8N.io, Etc. |
|
Static code review |
|
|
Dynamic code review |
|
|
CI/CD |
|
|
Agile Project Management |
|
|
|
|
|
AI / ML |
|
|
ML algorithms |
|
|
LLM planning, testing, management |
LLM Model pre-training, fine-tuning, embedding, prompt context, etc. |
|
TF / IDF |
|
|
AI proof-of-concept sandboxes |
Classification, summarization, Q/A, helpdesk, knowledge collaboration, learning systems and other key use cases |
|
Semantic embedding content for LLM's |
Transcend the limits of the context window! |
|
Statistical inference models for ML/AI apps |
|
|
AI Topic Modeling (LDA, BERTopic, LLMs) |
|
|
|
|
|
|
|
|
NLP / IR |
Natural Language Processing / Information Retrieval |
|
Natural Language Processing applications |
|
|
Search and retrieval technology |
|
|
Ontologies |
|
|
RDF, SPARQL |
|
|
Taxonomies |
|
|
Knowledge Graphs |
|
|
Conceptual Graphs |
|
|
Business Process Modeling |
|
|
Rhizomes |
|
|
|
|
|
UX / UI DESIGN |
|
|
Qualitative user research - Qual |
|
|
Quantitative usability testing - Quant |
|
|
Rapid UI prototyping |
Stateful hi-res prototypes for complex, interactive workflows |
|
Data Visualization design |
Authoritative charts, tables and visuals for analytics and data-driven apps. |
|
Cooper Scenario-based task analysis |
|
|
JTBD / OOUX |
|
|
Journey maps, personas, mental models |
|
|
Design systems |
|
|
Minimum Viable Product Planning |
Agile / UX interface |
|
|
|
|
SECURITY & COMPLIANCE |
|
|
Risk Analysis |
Risk Types: Security, Financial, Operational, Compliance, Reputational |
|
Source code security analysis |
|
|
Application security analysis |
|
|
AI based security analysis |
|
|
AI red/blue team design |
|
|
SOC2 |
|
|
GDPR |
|
|
WCAG / 508 / ADA |
|
|
Zero Trust networks |
|
|
Data Governance (Data Governance Audits) |
|
|
|
|
|
TECHNOLOGY LEADERSHIP |
|
|
Technical Evangelists. |
|
|
Technical Marketing and Sales |
|
|
White paper and presentation content creation |
|
|
R&D projects |
|
|
|
|
Please schedule a brainstorm session about your AI, NLP, ML, IR, chatbot/agent product and infrastructure challenges.
Free consultation: Schedule a call with Plexgraf
Let's brainstorm exponential opportunities together
Back to top